Practice Makes Perfect:
Planning to Learn Skill Parameter Policies
We enable a robot to rapidly and autonomously specialize parameterized skills by planning to practice them. The robot decides what skills to practice and how to practice them. The robot is left alone for hours, repeatedly practicing and improving.
Abstract
One promising approach towards effective robot decision making in complex, long-horizon tasks is to sequence together parameterized skills. We consider a setting where a robot is initially equipped with (1) a library of parameterized skills, (2) an AI planner for sequencing together the skills given a goal, and (3) a very general prior distribution for selecting skill parameters. Once deployed, the robot should rapidly and autonomously learn to improve its performance by specializing its skill parameter selection policy to the particular objects, goals, and constraints in its environment. In this work, we focus on the active learning problem of choosing which skills to practice to maximize expected future task success. We propose that the robot should estimate the competence of each skill, extrapolate the competence (asking: "how much would the competence improve through practice?"), and situate the skill in the task distribution through competence-aware planning. This approach is implemented within a fully autonomous system where the robot repeatedly plans, practices, and learns without any environment resets. Through experiments in simulation, we find that our approach learns effective parameter policies more sample-efficiently than several baselines. Experiments in the real-world demonstrate our approach's ability to handle noise from perception and control and improve the robot's ability to solve two long-horizon mobile-manipulation tasks after a few hours of autonomous practice.
Approach Walkthrough
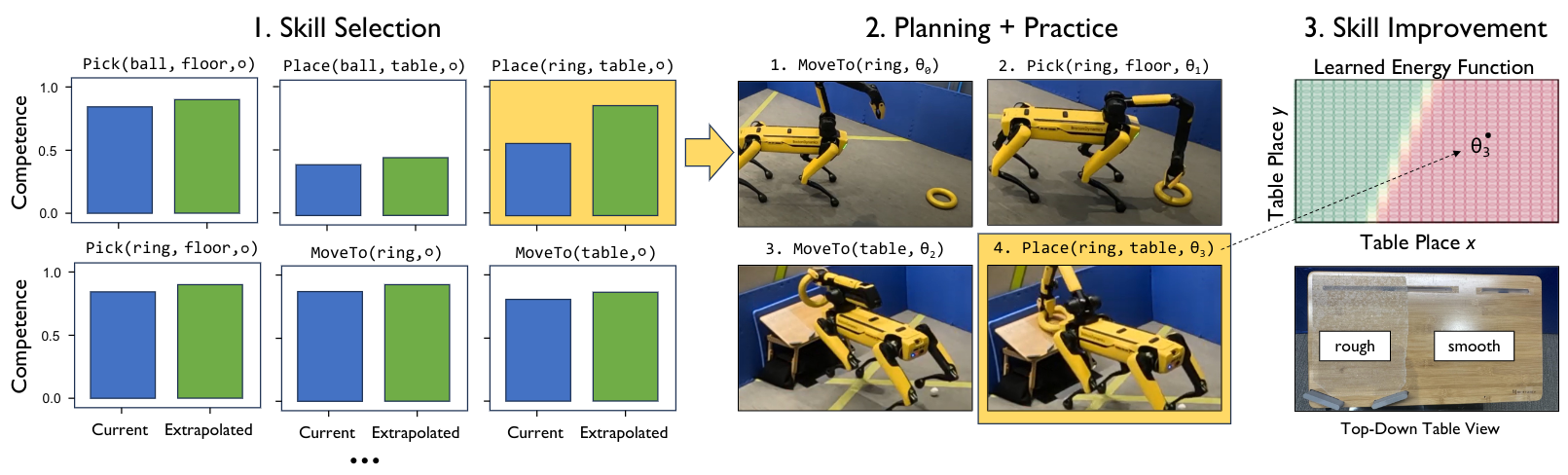
We propose Estimate, Extrapolate, and Situate (EES), an approach for planning to practice parameterized skills. During free time, the robot repeatedly chooses skills to practice. (Left) To select a skill, the robot first estimates each skill's competence, the probability that the skill will achieve its intended effects. The robot then extrapolates the competence, asking: "how much better would the skill get through practice?" Finally, the robot situates the competence, asking: "how much better overall at human-given tasks would I get by practicing this skill?" (Middle) Once a skill is selected, the robot plans to satisfy the skill's initiation condition and then practices the skill once. (Right) The practice data is used to improve the skill. Specifically, the robot learns parameter policies that choose good continuous parameters for the skill.
The video below illustrates EES in the Ball-Ring environment. Here, the robot is tasked with placing a ball stably on a table. Through interaction and repeated practice, EES enables the robot to learn that (1) the ball cannot be directly placed on the table because it is slanted and will always cause the ball to roll off, (2) the yellow ring can only be placed on the left side of the table, where there is a high-friction material that prevents it from sliding off, (3) the best way to accomplish the goal is to place the ring on the left side and then place the ball into the ring. EES is implemented on a real robot system that uses perception and planning to achieve robust performance, even in the presense of adversarial interventions.
Results
Simulated Environments
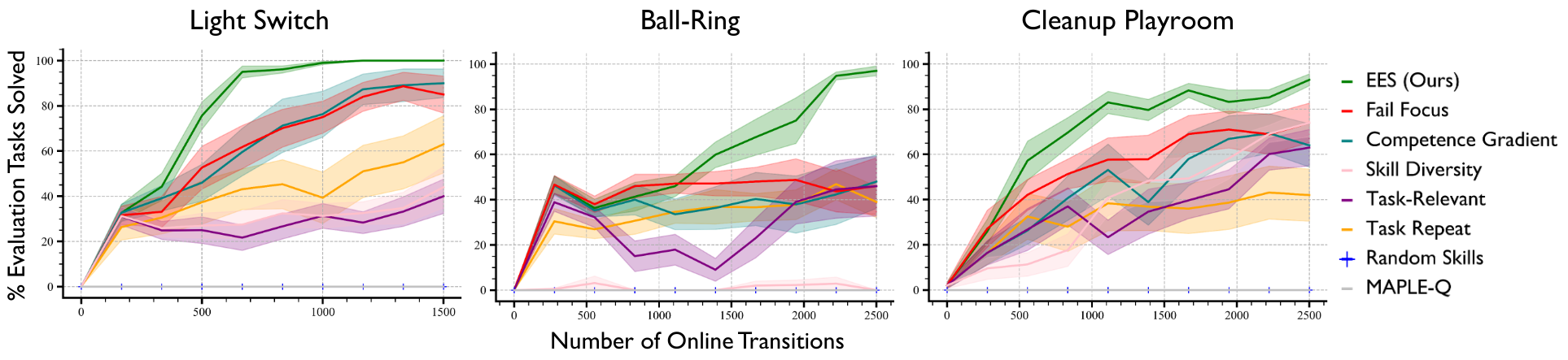
We compare EES to 7 baselines and find that it is consistently more sample-efficient across 3 simulated environments.
Real Robot Environments
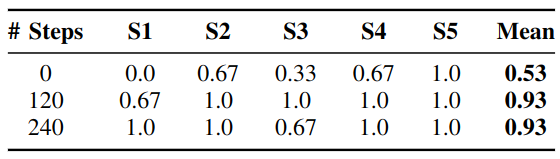
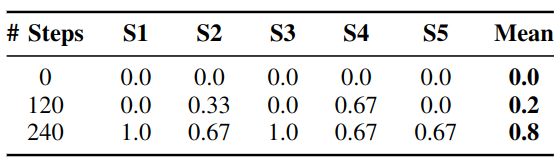
We implemented our approach on real-world versions of the simulated Ball-Ring and Cleanup Playroom environments. We measured the success rate under timeout across 5 random seeds. Results and accompanying demonstrative video of learning and evaluation are shown below. For full, uncut and unedited versions of the robot's practice in these environments, see the following links: Ball-Ring Uncut, Cleanup Playroom Uncut
Results over 5 Seeds
Results in the Cleanup Playroom Env
Limitations and Dirty Laundry
Our robot system implementation is far from perfect and has a number of limitations. We display and discuss some of them here in the hopes that this promotes transparency and inspires future work. For more specific technical details around system implementation and limitations, please see our paper and code linked above.
Dead-End States
A key assumption of our practicing framework is that the robot is always able to achieve the goal from any state it might ever encounter. This was made largely true in our environments, however, it did sometimes get violated in rare and unexpected circumstances, examples of which are shown below.


In the left image, the ring got stuck in a position from which the robot's pick skill is unable to succeed (it assumes the ring is flat on a surface, never upright). On the right, the ball got trapped below the table such that the robot was unable to see or grasp it. Below, we show an example of the robot accidentally getting into a dead-end state in the Cleanup Playroom environment.
Perception Errors
Our perception pipeline relies on a combination of Detic and SAM to perform object detection and segmentation from robot camera images. To get to a high level of reliability, this required significant tuning of language prompts describing objects that are input to Detic. Despite this, false positive detections still occur.


These misdetections are usually not catastrophic, but can cause substantial replanning and sometimes contribute to the robot getting into dead-end states mentioned above.
Skill Execution Errors
We leverage a library of skills to accomplish tasks, and each of these skills is prone to failures that cannot be improved even by practice...


Similar to perception errors, these skill failures are usually overcome by replanning, but they can sometimes lead to dead end states.
Object Finding
Our implementation features a relatively simple skill that attempts to navigate to random locations to find an object once its been lost (e.g., by having been dropped after moving). This can sometimes take a very long time to terminate.
Citation
@inproceedings{kumar2024practice,
title={Practice Makes Perfect: Planning to Learn Skill Parameter Policies},
author={Nishanth Kumar and Tom Silver and Willie McClinton and Linfeng Zhao and Stephen Proulx and Tomás Lozano-Pérez and Leslie Pack Kaelbling and Jennifer Barry},
year={2024},
booktitle={Robotics: Science and Systems (RSS)}
}